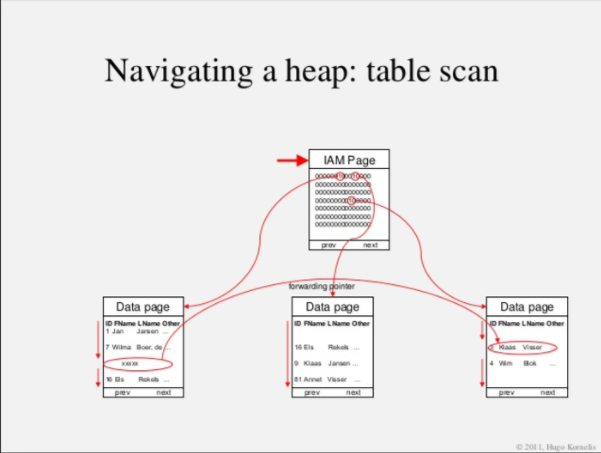
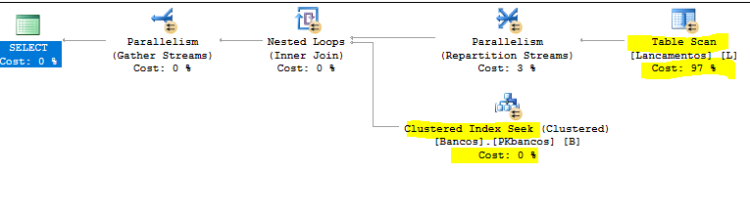
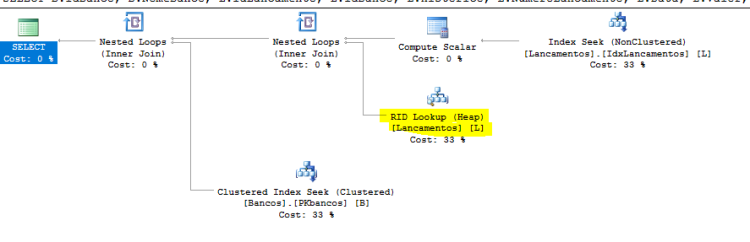
Hoje vamos ver uma funcionalidade interessante das Views,e esse post aqui por si foi muito além do que eu imaginava.
Nossa missão hoje e otimizar acesso a uma tabela com 1 milhão de registros,
Vamos criar uma partitioned-views e alem disso ela deve ser MODIFICÁVEL
ou seja deve receber Inserts , deletes , Updates.
Views particionadas surgiu no sql server 2000, alguns gostam outros não , outras funcionalidades foram criadas como por exemplo partition table ,mas como views particionadas e uma funcionalidade a ser entendida , então entender-la:
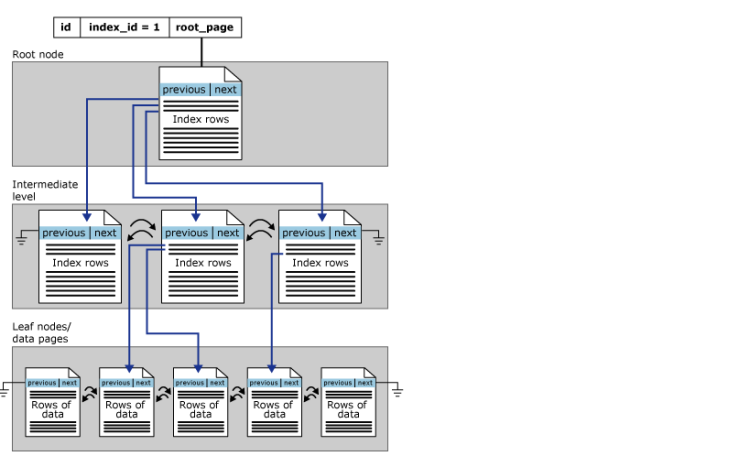
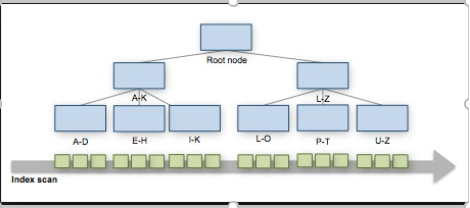
Conceito: As views particionadas permitem que os dados de uma tabela grande sejam divididos em tabelas membro menores. Os dados são particionados entre as tabelas membro com base nos intervalos dos valores de dados de uma das colunas. Os intervalos de dados para cada tabela membro estão definidos em uma restrição CHECK especificada na coluna de particionamento
Não se trata de partição de tabelas, o nosso caso de uso e ser resolvido trata-se de problemas de performance, processos de IO,
A sintaxe e bem simples.
CREATE VIEW dbo.VwMyView
AS
SELECT as colunas …
from tabela1
UNION ALL
SELECT as colunas …
from tabela 2
UNION ALL
SELECT as colunas …
from tabela 3
SELECT * FROM dbo.VwMyView
Cada tabela em uma visão particionada é sua própria pequena (ou grande) ilha de dados. Ao contrário do particionamento, onde as partições se juntam para formar uma unidade lógica. Por exemplo, se você executar o ALTER TABLE em uma tabela particionada, você altera a tabela inteira
Caso de uso:
Nosso cliente da XPTO tem uma tabela com 1 milhão de registros que são lançamentos bancários para dois grandes bancos, poderia ser 2 , 10 ,100 milhões mas vamos começar com 1 milhão, e diversas procedures fazem referencias a ela fazendo scan na tabela inteira, então decidimos ajudar.
vamos a demo:
O código abaixo apenas cria um banco com duas tabelas , uma para Conta bancaria e outra de Lançamentos
-- ==================================================================
–Observação:Cria o banco de dados com as tabelas para exemplo
— ==================================================================
CREATE DATABASE ExemploViewParticionada;
GO
USE ExemploViewParticionada;
IF ( OBJECT_ID(‘ContaBancaria’, ‘U’) IS NULL )
BEGIN
CREATE TABLE ContaBancaria
(
idContaBancaria UNIQUEIDENTIFIER NOT NULL PRIMARY KEY ROWGUIDCOL DEFAULT ( NEWSEQUENTIALID() ) ,
NomeConta VARCHAR(30)
);
INSERT dbo.ContaBancaria( NomeConta )VALUES ( ‘CEF’ ),( ‘BB’ );
END;
IF ( OBJECT_ID(‘Lancamentos’, ‘U’) IS NULL )
BEGIN
CREATE TABLE Lancamentos
(
idLancamento UNIQUEIDENTIFIER NOT NULL ROWGUIDCOL DEFAULT ( NEWSEQUENTIALID() ) ,
idContaBancaria UNIQUEIDENTIFIER NOT NULL FOREIGN KEY ( idContaBancaria ) REFERENCES dbo.ContaBancaria ( idContaBancaria ) ,
Historico VARCHAR(100) NOT NULL DEFAULT ( ‘Histórico padrão para lançamentos bancários.’ ) ,
NumeroLancamento INT NOT NULL ,
Data DATETIME ,
Valor DECIMAL(18, 2) ,
Credito BIT NOT NULL,
CONSTRAINT PKLancamentos PRIMARY KEY(idLancamento,Data)
);
END;
Agora vamos gerar um insert para a tabela de lançamentos gerando 1 milhão de registros balanceando entre os anos de 2011 até 2017, esse script demora cerca de 1 minuto.
— ==================================================================
–Observação:faz insert dos dados com valores aleatórios
— ==================================================================
DECLARE @dataInicio DATETIME = ‘2011-01-01’;
DECLARE @IsCredito BIT = 1;
DECLARE @IdContaBancariaCEF UNIQUEIDENTIFIER = ( SELECT TOP 1
CB.idContaBancaria
FROM dbo.ContaBancaria
AS CB
WHERE CB.NomeConta = ‘CEF’
);
DECLARE @IdContaBancariaBB UNIQUEIDENTIFIER = ( SELECT TOP 1
CB.idContaBancaria
FROM dbo.ContaBancaria AS CB
WHERE CB.NomeConta = ‘BB’
);
WITH CTE
AS ( SELECT 1 AS NumeroLancamento
UNION ALL
SELECT CTE.NumeroLancamento + 1
FROM CTE
WHERE CTE.NumeroLancamento < 1000000
),
Query
AS ( SELECT CTE.NumeroLancamento ,
TA.IdConta ,
TA.Data ,
TA.Valor ,
TA.Credito
FROM CTE
CROSS APPLY ( SELECT CASE WHEN ( CTE.NumeroLancamento
% 2 = 0 )
THEN @IdContaBancariaCEF
ELSE @IdContaBancariaBB
END AS IdConta ,
CAST(DATEADD(DAY,
ABS(CHECKSUM(NEWID())
% IIF(( CTE.NumeroLancamento <= 800000 ), 2555, 730)),
IIF(( CTE.NumeroLancamento <= 800000 ), ‘2011-01-01’, ‘2016-01-01’)) AS DATE) AS Data ,
CAST(ABS(CAST(( CAST(CHECKSUM(NEWID()) AS DECIMAL(18,
2)) / 1000000 ) AS DECIMAL(18,
2))) AS DECIMAL(18,
2)) AS Valor ,
IIF(( CTE.NumeroLancamento <= 600000 ), 0, 1) AS Credito
) AS TA
)
INSERT INTO dbo.Lancamentos WITH ( TABLOCK )
( idContaBancaria ,
NumeroLancamento ,
Data ,
Valor ,
Credito
)
SELECT Q.IdConta ,
Q.NumeroLancamento ,
Q.Data ,
Q.Valor ,
Q.Credito
FROM Query Q
OPTION ( MAXRECURSION 0 );
vamos analisar a distribuição de dados
— ==================================================================
SELECT Ano = YEAR(L.Data) ,
QuantidadeLancamento = FORMAT(COUNT(*), ‘N’, ‘pt-Br’)
FROM dbo.Lancamentos AS L
GROUP BY YEAR(L.Data)
ORDER BY YEAR(L.Data);
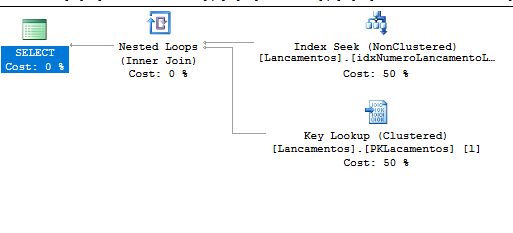
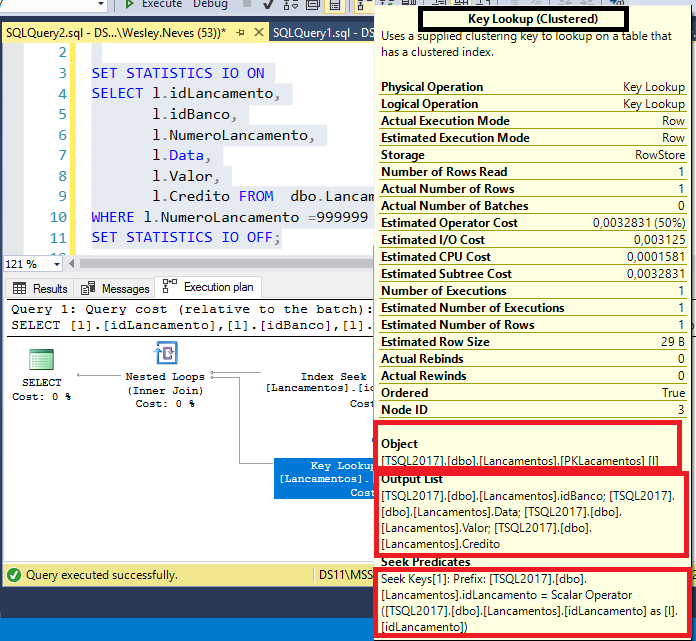
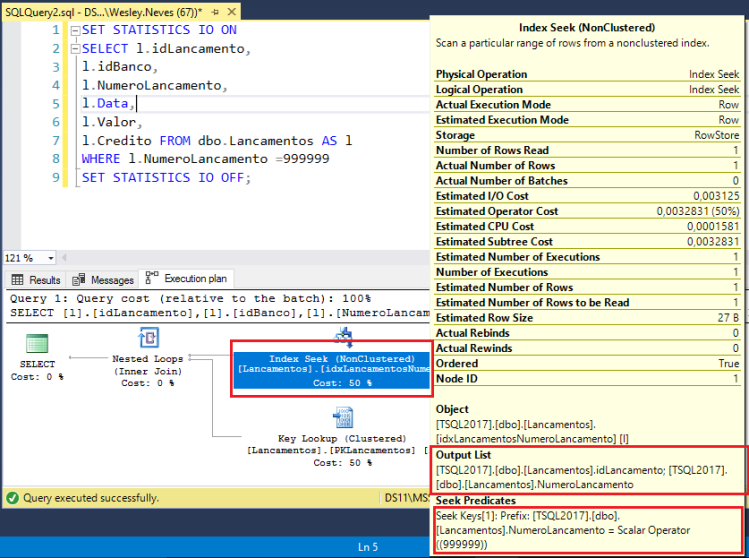
Nosso desafio e fazer uma forma de acesso para quando for buscado os registros de 2011 só leia as paginas referentes a registros de 2011 caso for buscado os registros de 2012 as rotinas só leia as paginas de 2012, e assim por diante.
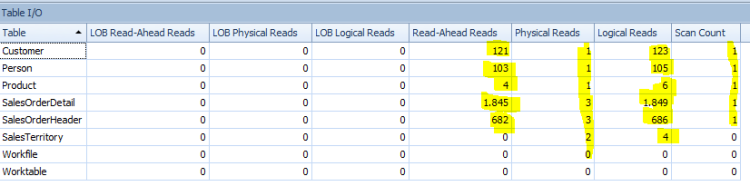
habilitando SET STATISTICS IO ON temos os seguintes dados
-- ==================================================================
— Vamos ver o tamanho da tabela em paginas
— ==================================================================
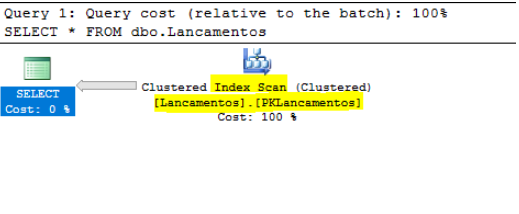
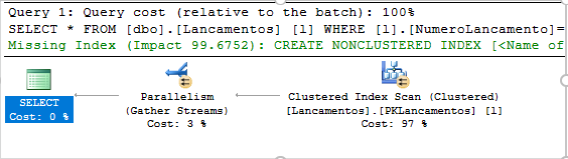
SELECT * FROM dbo.Lancamentos AS L –logical reads 14011,
SELECT ‘Tamanho em MB’, (14011 * 8) / 1024
Agora vamos criar as tabelas referentes a cada ano, de 2011 até 2016, o que vai mudar é a CONSTRAINT CHECK que terá a regra de particionamento.
— ==================================================================
— Cria as tabelas para cada ano
— ==================================================================
CREATE TABLE LancamentosAno2011
(
idLancamento UNIQUEIDENTIFIER NOT NULL ROWGUIDCOL ,
idContaBancaria UNIQUEIDENTIFIER NOT NULL
FOREIGN KEY ( idContaBancaria ) REFERENCES dbo.ContaBancaria ( idContaBancaria ) ,
Historico VARCHAR(100) NOT NULL ,
NumeroLancamento INT NOT NULL ,
Data DATETIME NOT NULL ,
Valor DECIMAL(18, 2) ,
Credito BIT NOT NULL ,
CONSTRAINT PKidLancamento2011 PRIMARY KEY CLUSTERED ( idLancamento ,Data),
CONSTRAINT CkDataAno2011 CHECK ( Data >=‘2011-01-01 00:00:00’ AND Data <=‘2011-12-31 23:59:57’)
);
CREATE TABLE LancamentosAno2012
(
idLancamento UNIQUEIDENTIFIER NOT NULL
ROWGUIDCOL ,
idContaBancaria UNIQUEIDENTIFIER
NOT NULL
FOREIGN KEY ( idContaBancaria ) REFERENCES dbo.ContaBancaria ( idContaBancaria ) ,
Historico VARCHAR(100) NOT NULL ,
NumeroLancamento INT NOT NULL ,
Data DATETIME NOT NULL,
Valor DECIMAL(18, 2) ,
Credito BIT NOT NULL ,
CONSTRAINT PKidLancamento2012 PRIMARY KEY CLUSTERED ( idLancamento,Data),
CONSTRAINT CkDataAno2012 CHECK ( Data >=‘2012-01-01 00:00:00’ AND Data <=‘2012-12-31 23:59:57’)
);
CREATE TABLE LancamentosAno2013
(
idLancamento UNIQUEIDENTIFIER NOT NULL
ROWGUIDCOL ,
idContaBancaria UNIQUEIDENTIFIER
NOT NULL
FOREIGN KEY ( idContaBancaria ) REFERENCES dbo.ContaBancaria ( idContaBancaria ) ,
Historico VARCHAR(100) NOT NULL ,
NumeroLancamento INT NOT NULL ,
Data DATETIME NOT NULL ,
Valor DECIMAL(18, 2) ,
Credito BIT NOT NULL ,
CONSTRAINT PKidLancamento2013 PRIMARY KEY CLUSTERED ( idLancamento,Data),
CONSTRAINT CkDataAno2013 CHECK ( Data >=‘2013-01-01 00:00:00’ AND Data <=‘2013-12-31 23:59:57’)
);
CREATE TABLE LancamentosAno2014
(
idLancamento UNIQUEIDENTIFIER NOT NULL
ROWGUIDCOL ,
idContaBancaria UNIQUEIDENTIFIER
NOT NULL
FOREIGN KEY ( idContaBancaria ) REFERENCES dbo.ContaBancaria ( idContaBancaria ) ,
Historico VARCHAR(100) NOT NULL ,
NumeroLancamento INT NOT NULL ,
Data DATETIME NOT NULL ,
Valor DECIMAL(18, 2) ,
Credito BIT NOT NULL ,
CONSTRAINT PKidLancamento2014 PRIMARY KEY CLUSTERED ( idLancamento,Data ),
CONSTRAINT CkDataAno2014 CHECK ( Data >=‘2014-01-01 00:00:00’ AND Data <=‘2014-12-31 23:59:57’)
);
CREATE TABLE LancamentosAno2015
(
idLancamento UNIQUEIDENTIFIER NOT NULL
ROWGUIDCOL ,
idContaBancaria UNIQUEIDENTIFIER
NOT NULL
FOREIGN KEY ( idContaBancaria ) REFERENCES dbo.ContaBancaria ( idContaBancaria ) ,
Historico VARCHAR(100) NOT NULL ,
NumeroLancamento INT NOT NULL ,
Data DATETIME ,
Valor DECIMAL(18, 2) ,
Credito BIT NOT NULL ,
CONSTRAINT PKidLancamento2015 PRIMARY KEY CLUSTERED ( idLancamento ,Data),
CONSTRAINT CkDataAno2015 CHECK ( Data >=‘2015-01-01 00:00:00’ AND Data <=‘2015-12-31 23:59:57’)
);
CREATE TABLE LancamentosAno2016
(
idLancamento UNIQUEIDENTIFIER NOT NULL
ROWGUIDCOL ,
idContaBancaria UNIQUEIDENTIFIER
NOT NULL
FOREIGN KEY ( idContaBancaria ) REFERENCES dbo.ContaBancaria ( idContaBancaria ) ,
Historico VARCHAR(100) NOT NULL ,
NumeroLancamento INT NOT NULL ,
Data DATETIME NOT NULL,
Valor DECIMAL(18, 2) ,
Credito BIT NOT NULL ,
CONSTRAINT PKidLancamento2016 PRIMARY KEY CLUSTERED ( idLancamento,Data),
CONSTRAINT CkDataAno2016 CHECK ( Data >=‘2016-01-01 00:00:00’ AND Data <=‘2016-12-31 23:59:57’)
);
Agora para cada ano vamos inserir os registros na tabela respectiva.
#Code faz os inserts para cada ano.
— ==================================================================
–Agora vamos executar o insert nessas tabelas, cada tabela criada
— terá os lançamentos do seu ano
— ==================================================================
INSERT INTO dbo.LancamentosAno2011
( idLancamento ,
idContaBancaria ,
Historico ,
NumeroLancamento,
Data ,
Valor ,
Credito
)
SELECT L.idLancamento ,
L.idContaBancaria ,
L.Historico ,
L.NumeroLancamento,
L.Data ,
L.Valor ,
L.Credito
FROM dbo.Lancamentos AS L
WHERE YEAR(L.Data) = 2011;
INSERT INTO dbo.LancamentosAno2012
( idLancamento ,
idContaBancaria ,
Historico ,
NumeroLancamento,
Data ,
Valor ,
Credito
)
SELECT L.idLancamento ,
L.idContaBancaria ,
L.Historico ,
L.NumeroLancamento,
L.Data ,
L.Valor ,
L.Credito
FROM dbo.Lancamentos AS L
WHERE YEAR(L.Data) = 2012;
INSERT INTO dbo.LancamentosAno2013
( idLancamento ,
idContaBancaria ,
Historico ,
NumeroLancamento,
Data ,
Valor ,
Credito
)
SELECT L.idLancamento ,
L.idContaBancaria ,
L.Historico ,
L.NumeroLancamento,
L.Data ,
L.Valor ,
L.Credito
FROM dbo.Lancamentos AS L
WHERE YEAR(L.Data) = 2013;
INSERT INTO dbo.LancamentosAno2014
( idLancamento ,
idContaBancaria ,
Historico ,
NumeroLancamento,
Data ,
Valor ,
Credito
)
SELECT L.idLancamento ,
L.idContaBancaria ,
L.Historico ,
L.NumeroLancamento,
L.Data ,
L.Valor ,
L.Credito
FROM dbo.Lancamentos AS L
WHERE YEAR(L.Data) = 2014;
INSERT INTO dbo.LancamentosAno2015
( idLancamento ,
idContaBancaria ,
Historico ,
NumeroLancamento,
Data ,
Valor ,
Credito
)
SELECT L.idLancamento ,
L.idContaBancaria ,
L.Historico ,
L.NumeroLancamento,
L.Data ,
L.Valor ,
L.Credito
FROM dbo.Lancamentos AS L
WHERE YEAR(L.Data) = 2015;
INSERT INTO dbo.LancamentosAno2016
( idLancamento ,
idContaBancaria ,
Historico ,
NumeroLancamento,
Data ,
Valor ,
Credito
)
SELECT L.idLancamento ,
L.idContaBancaria ,
L.Historico ,
L.NumeroLancamento,
L.Data ,
L.Valor ,
L.Credito
FROM dbo.Lancamentos AS L
WHERE YEAR(L.Data) = 2016;
— ==================================================================
— Deleta os lançamentos que foram migrados para as outras tabelas
— ==================================================================
DELETE L
FROM dbo.Lancamentos AS L
JOIN ( SELECT LA.idLancamento
FROM dbo.LancamentosAno2011 AS LA
UNION ALL
SELECT LA.idLancamento
FROM dbo.LancamentosAno2012 AS LA
UNION ALL
SELECT LA.idLancamento
FROM dbo.LancamentosAno2013 AS LA
UNION ALL
SELECT LA.idLancamento
FROM dbo.LancamentosAno2014 AS LA
UNION ALL
SELECT LA.idLancamento
FROM dbo.LancamentosAno2015 AS LA
UNION ALL
SELECT LA.idLancamento
FROM dbo.LancamentosAno2016 AS LA
) AS LANAntigo ON LANAntigo.idLancamento = L.idLancamento
— ==================================================================
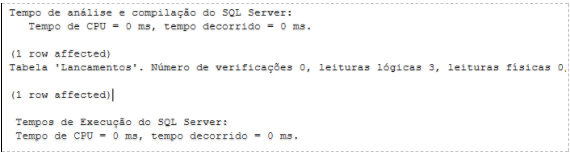
–Aqui temos um ponto de atenção,
–acabamos de rodar um DELETE em mais ou menos (750000 mil linhas)
–e mesmo assim temos logical reads 14011,
— ==================================================================
SET STATISTICS IO ON;
SELECT *
FROM dbo.Lancamentos AS L;
SET STATISTICS IO OFF;
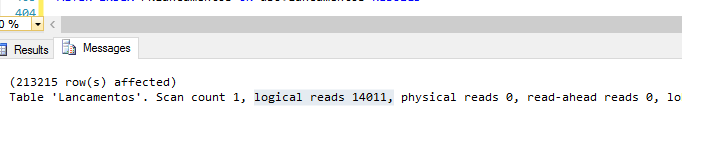
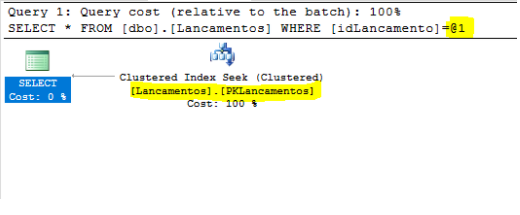
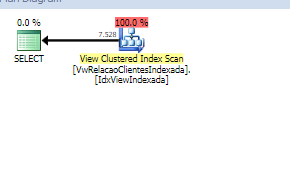
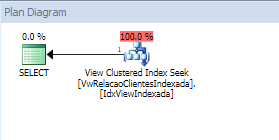
Isso e motivado pela fragmentação do índice ,para isso vamos fazer um REBUILD
ALTER INDEX PKLancamentos ON dbo.Lancamentos REBUILD
rode novamente para ver a quantidade de paginas agora
SET STATISTICS IO ON;
SELECT *
FROM dbo.Lancamentos AS L;
SET STATISTICS IO OFF;
— ==================================================================
–Agora vamos criar a chave de particionamento da tabela
— ==================================================================
ALTER TABLE dbo.Lancamentos ADD CONSTRAINT CkDataLancamento2017 CHECK ( Data >= ‘2017-01-01 00:00:00’);
— ==================================================================
–Agora vamos criar a View Particionada, como o nosso objetivo e ter uma view que receba comandos DML precisamos retornar todas as colunas.
— ==================================================================
CREATE VIEW VwBuscaLancamentos AS
SELECT LA.idLancamento ,
LA.idContaBancaria ,
LA.Historico ,
La.NumeroLancamento,
LA.Data ,
LA.Valor ,
LA.Credito
FROM dbo.LancamentosAno2011 AS LA — logical reads 1606,
UNION ALL
SELECT LA.idLancamento ,
LA.idContaBancaria ,
LA.Historico ,
La.NumeroLancamento,
LA.Data ,
LA.Valor ,
LA.Credito
FROM dbo.LancamentosAno2012 AS LA –logical reads 1615
UNION ALL
SELECT LA.idLancamento ,
LA.idContaBancaria ,
LA.Historico ,
La.NumeroLancamento,
LA.Data ,
LA.Valor ,
LA.Credito
FROM dbo.LancamentosAno2013 AS LA — logical reads 1599
UNION ALL
SELECT LA.idLancamento ,
LA.idContaBancaria ,
LA.Historico ,
La.NumeroLancamento,
LA.Data ,
LA.Valor ,
LA.Credito
FROM dbo.LancamentosAno2014 AS LA –logical reads 1601
UNION ALL
SELECT LA.idLancamento ,
LA.idContaBancaria ,
LA.Historico ,
La.NumeroLancamento,
LA.Data ,
LA.Valor ,
LA.Credito
FROM dbo.LancamentosAno2015 AS LA –logical reads 1611
UNION ALL
SELECT LA.idLancamento ,
LA.idContaBancaria ,
LA.Historico ,
La.NumeroLancamento,
LA.Data ,
LA.Valor ,
LA.Credito
FROM dbo.LancamentosAno2016 AS LA –logical reads 3001
UNION ALL
SELECT LA.idLancamento ,
LA.idContaBancaria ,
LA.Historico ,
La.NumeroLancamento,
LA.Data ,
LA.Valor ,
LA.Credito
FROM dbo.Lancamentos AS LA; — logical reads 2977
GO
–Pronto temos nossa View particionada , agora vamos a alguns testes.
SET STATISTICS IO ON;
–Registros de 2011
SELECT COUNT(*)
FROM dbo.VwBuscaLancamentos AS VBL
WHERE VBL.Data >=‘2011-01-01’ AND Data <=‘2011-12-31’
(1 row(s) affected)
Table ‘LancamentosAno2011’. Scan count 1, logical reads 1606,
–Registros de 2012
SELECT COUNT(*)
FROM dbo.VwBuscaLancamentos AS VBL
WHERE VBL.Data >=‘2012-01-01’ AND Data <=‘2012-12-31’
(1 row(s) affected)
Table ‘LancamentosAno2012’. Scan count 1, logical reads 1615,
–Registros de 2013
SELECT COUNT(*)
FROM dbo.VwBuscaLancamentos AS VBL
WHERE VBL.Data >=‘2013-01-01’ AND Data <=‘2013-12-31’
(1 row(s) affected)
Table ‘LancamentosAno2013’. Scan count 1, logical reads 1599,
–Registros entre 2015-01-01 a 2016-12-31
SELECT COUNT(*)
FROM dbo.VwBuscaLancamentos AS VBL
WHERE VBL.Data >=‘2015-01-01’ AND Data <=‘2016-12-31’
Table ‘LancamentosAno2016’. Scan count 1, logical reads 3001,
Table ‘LancamentosAno2015’. Scan count 1, logical reads 1611,
–registros a partir de 2017
SELECT *
FROM dbo.VwBuscaLancamentos AS VBL
WHERE VBL.Data >=‘2017-01-01’
(213215 row(s) affected)
Table ‘Lancamentos’. Scan count 1, logical reads 2977,
As consulta pode ser executada mais rapidamente porque o SQL Server está fazendo menos trabalho.
Agora Vamos Aos Inserts ,Deletes e Updates na View particionada.
TRUNCATE TABLE dbo.LancamentosAno2011
TRUNCATE TABLE dbo.LancamentosAno2012
TRUNCATE TABLE dbo.LancamentosAno2013
TRUNCATE TABLE dbo.LancamentosAno2014
TRUNCATE TABLE dbo.LancamentosAno2015
TRUNCATE TABLE dbo.LancamentosAno2016
TRUNCATE TABLE dbo.Lancamentos
— ==================================================================
–Com as tabelas vazias vamos fazer os Inserts
–Primeira observação , a view só podera responder por insert se todos os campos das tabelas forem retornada por ela
–ou seja se vc omitir um campo das tabelas a view não poderá sofrer inserts ,
— ==================================================================
SELECT * FROM dbo.VwBuscaLancamentos AS VBL
–Recuperar a chave gerada
DECLARE @idconta UNIQUEIDENTIFIER=(SELECT TOP 1 CB.idContaBancaria FROM dbo.ContaBancaria AS CB)
INSERT INTO dbo.VwBuscaLancamentos
( idLancamento ,idContaBancaria , Historico ,NumeroLancamento ,Data , Valor ,Credito)
VALUES ( NEWID(), @idconta ,‘Lancamento 2011’ ,1,‘2011-02-10’, 100,1 );
INSERT INTO dbo.VwBuscaLancamentos
( idLancamento ,idContaBancaria , Historico ,NumeroLancamento ,Data , Valor ,Credito)
VALUES ( NEWID(),@idconta,‘Lancamento 2012’ ,1,‘2012-05-10’, 100,1 );
INSERT INTO dbo.VwBuscaLancamentos
( idLancamento ,idContaBancaria , Historico ,NumeroLancamento ,Data , Valor ,Credito)
VALUES ( NEWID(),@idconta ,‘Lancamento 2013’ ,1,‘2013-05-10’, 100,1 );
INSERT INTO dbo.VwBuscaLancamentos
( idLancamento ,idContaBancaria , Historico ,NumeroLancamento ,Data , Valor ,Credito)
VALUES ( NEWID(),@idconta ,‘Lancamento 2014’ ,1,‘2014-05-10’, 100,1 );
INSERT INTO dbo.VwBuscaLancamentos
( idLancamento ,idContaBancaria , Historico ,NumeroLancamento ,Data , Valor ,Credito)
VALUES ( NEWID(),@idconta ,‘Lancamento 2015’ ,1,‘2015-05-10’, 100,1 );
INSERT INTO dbo.VwBuscaLancamentos
( idLancamento ,idContaBancaria , Historico ,NumeroLancamento ,Data , Valor ,Credito)
VALUES ( NEWID(),@idconta ,‘Lancamento 2016’ ,1,‘2016-10-10’, 100,1 );
INSERT INTO dbo.VwBuscaLancamentos
( idLancamento ,idContaBancaria , Historico ,NumeroLancamento ,Data , Valor ,Credito)
VALUES ( NEWID(),@idconta ,‘Lancamento 2019’ ,1,‘2019-10-10’, 100,1 );
vc já viu comando de UPDATE fazendo por trás dos panos insert e deletes ??? se não
veja só
— ==================================================================
— rode esses dois selects primeiro , apos rode o update
— ==================================================================
SELECT * FROM dbo.LancamentosAno2011 AS LA
SELECT * FROM dbo.Lancamentos AS L
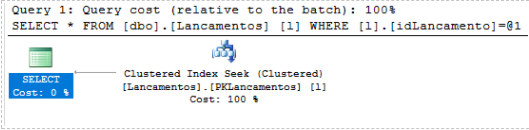
UPDATE dbo.VwBuscaLancamentos SET Data =‘2019-10-10’ WHERE Historico =‘Lancamento 2011’
SELECT * FROM dbo.LancamentosAno2011 AS LA
SELECT * FROM dbo.Lancamentos AS L
–Agora o Delete
SET STATISTICS IO ON
DELETE VBL FROM dbo.VwBuscaLancamentos AS VBL
WHERE VBL.Data = ‘2014-05-10 00:00:00.000’
SET STATISTICS IO OFF

E isso aee, muito poderosa essa solução , até a proxima.
Referencias :
https://technet.microsoft.com/en-us/library/ms187067(v=sql.105).aspx
https://www.brentozar.com/archive/2016/09/partitioned-views-guide/
http://sqlmag.com/blog/partitioned-tables-v-partitioned-views-why-are-they-even-still-around
What is a Partitioned View?